UCloud优刻得为了帮助企业降低容器和Kubernetes的使用门槛,UCloud优刻得在2020年7月份推出一款Serverless容器实例服务Cube,UCloud优刻得用户通过Cube用户只需要提供打包好的Docker镜像,即可快速、批量部署容器化应用,并且只需为容器实际运行消耗的资源付费。
随着容器、Kubernetes、Serverless等云原生技术的快速发展,越来越多的企业开始拥抱云原生。UCloud优刻得使用容器缩短了企业应用从开发、构建到发布、运行的整个生命周期,但由于Docker往往难以独立支撑起大规模容器化部署,因此诞生了Kubernetes等容器编排工具。然而Kubernetes的使用体系非常复杂,对于企业的开发运维人员而言,需要具备一定的网络、存储、系统等方面的技术能力。
这样一款Serverless产品,究竟是如何在技术上实现的呢?就在10月23日刚结束的UCloud优刻得TIC2020大会的技术分论坛上,UCloud优刻得容器云研发负责人张苗磊在《UCloud Cube容器技术解析》议题中着重介绍了UCloud优刻得 Cube产品背后的技术架构,并且从虚拟化/网络/存储等多方面展示无服务器化容器的技术细节。本文是演讲内容整理,供大家学习参考。

为什么要推出Cube?
说到云原生的概念,张苗磊讲到,云原生其实对云厂商带来很大的冲击,其中一个比较明显的变化就是用户需求和云厂商提供的能力之间的变化。
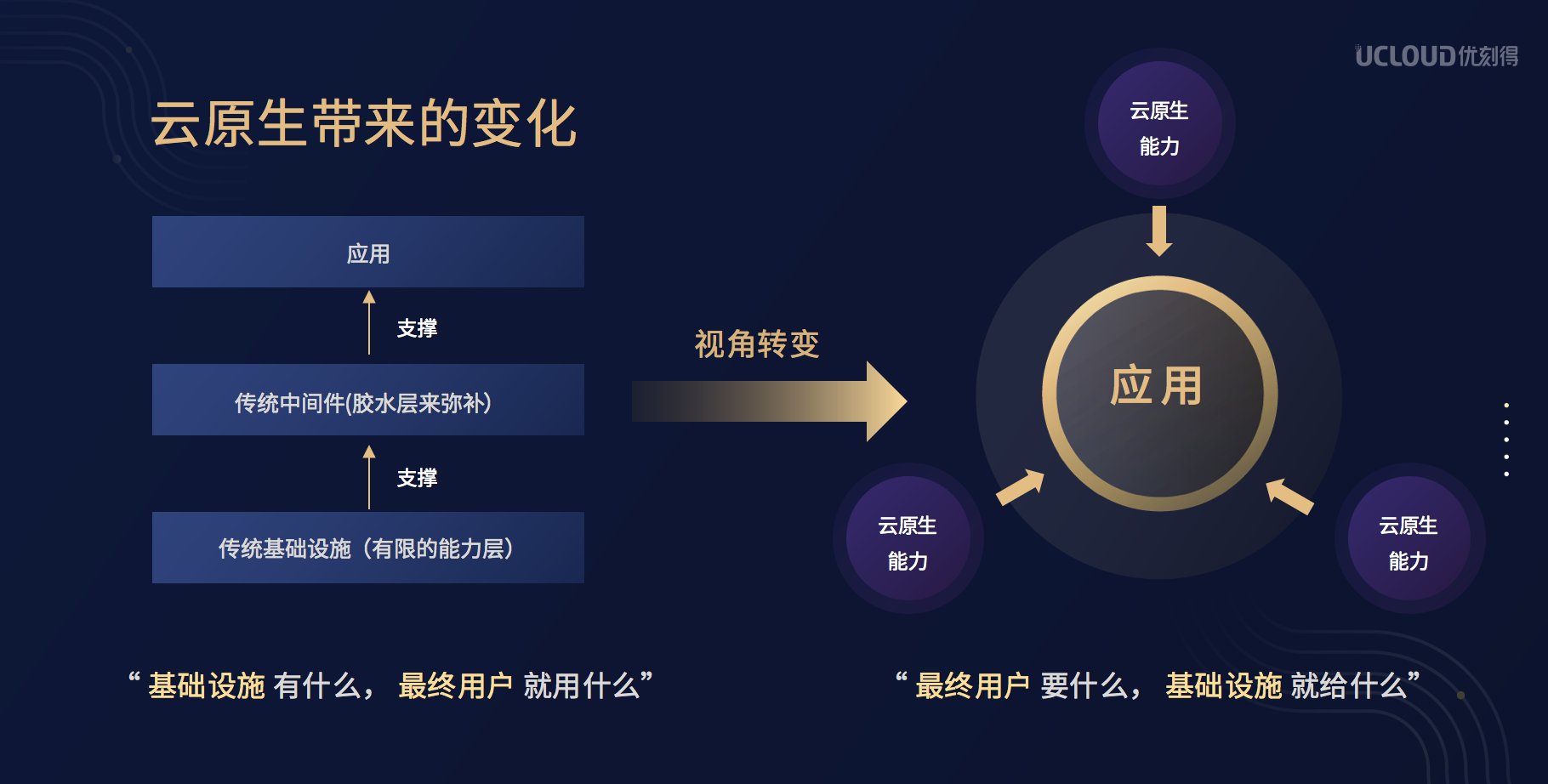
在云原生之前,用户从云厂商购买的是比较基础的计算能力和服务器资源,用户需要在此基础上一层层封装,最终来实现支撑自己应用服务的能力。而在云原生之后,云厂商则希望提供一种能够更加向应用靠拢的能力,用户仅仅需要关心应用,而其他所有的业务完全都可以交给云厂商来实现。
在此基础上,就很自然的诞生了所有Serverless产品的概念,即用户不需要再购买具体的服务器资源,而仅仅需要将它应用封装成一个比较标准的格式传递给云厂商,然后调用云厂商的API来直接运行它的程序,所需要的资源完全按需并且弹性灵活。
Serverless的概念在业界有很多具体的实现,比如容器和K8S就是一个比较好的例子,容器提供了对应用的封装,而K8S产品提供了对运行环境的管理。因此近年来包括UCloud优刻得在内的云厂商都推出了自己的K8S产品,即用户可以一键在云主机内构建一个K8S集群,K8S所需的其他能力完全由云厂商的插件来提供。
但是在K8S产品的推广过程中,我们发现K8S的概念还是比较复杂。用户在关心其应用的同时还要学习K8S知识,这是有些背离最初云原生提出的,仅以应用为中心的设计目标的。因此我们就想着能否进一步包装K8S的产品,仅将K8S最小的运行单元pod的概念暴露给用户,而其他所有的能力完全交给云厂商来实现。在此基础上,我们想能否将K8S的最小运行单元pod直接暴露出来,而将其他K8S繁琐的概念统统封装起来?

这样一来,我们就推出了一款Serverless容器实例服务Cube,Cube对外仅暴露pod的概念,而用户所需要的镜像运行命令和其他资源关联的关系都可以通过标准的K8S yaml提交给UCloud API。这样pod就可以轻松直接运行起来,用户实际所需要负责的,仅仅是pod所需要的资源大小。
Cube实现背后的技术原理
轻量级运行时
我们知道原生的docker实现,由于不能很好的做到资源隔离和租户隔离,因此无法在云厂商上直接暴露给用户。于是我们的Cube对docker运行时进行了大量的改造。

图中可以看到标准的虚拟机内实现的容器是左边所示,QEMU提供了虚拟机的隔离能力,而用户在QEMU虚拟机内会部署一个完整的docker或者containerd,并在此基础上拉起容器。我们在想能否将QEMU和虚拟机的二者能力结合为一起。于是在Cube中我们基于虚拟机实现了容器实例即我们的Cube,对外暴露的是标准的K8S CRI接口,但具体的实现是一个轻量级的虚拟机,用户实际需要运行的容器是在轻量级的虚拟机内拉起的。这样带来的好处是Cube融合了虚拟机资源隔离和容器快速启动的优点。
当然为了完全的比拟docker,实现的容器快速启动,我们在性能上也做了很多优化,比如将QEMU虚拟机换成了Firecracker轻量级虚拟机,仅实现了最小设备,进一步的降低虚拟化损耗。并且拉起速度能够降低到100毫秒。
当然容器的快速启动时间,也不仅包括容器启动的时间,还包括了镜像拉取的时间。我们在实际的应用推广过程中,也发现经常会遇到用户的容器特别大,而导致镜像拉取时间很长,进而导致启动速度慢。
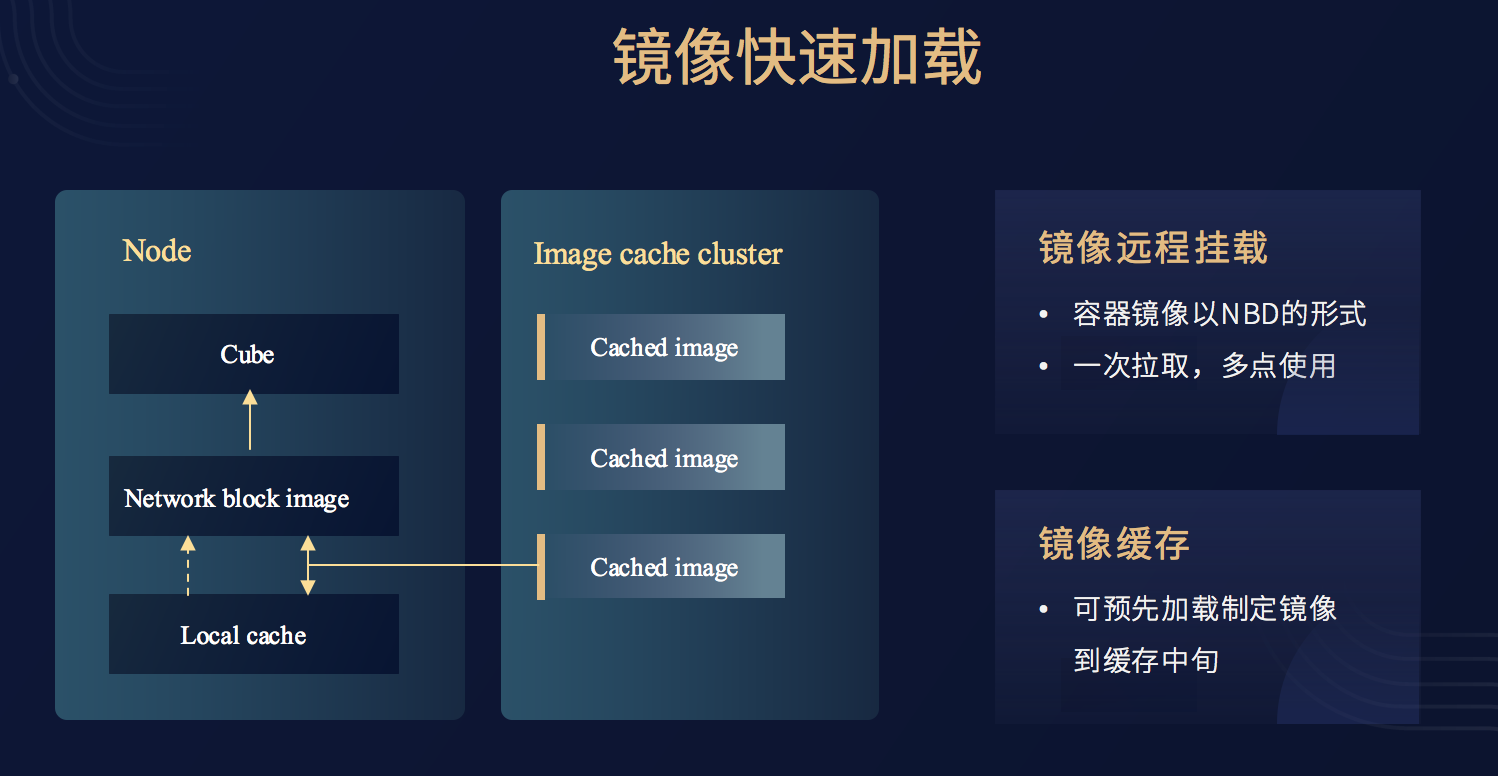
为了解决这种问题,我们实现了镜像缓存的功能。即用户的实际镜像拉取在第一次拉取中,会缓存在我们的镜像缓存中心,而后的镜像加载是直接通过NBD的形式直接挂载到Cube容器里,这样就可以实现Cube的快速启动,从而跳过了镜像拉取的时间。对于特别大的镜像,用户也可以选择预先加载的形式直接加载到我们的镜像缓存中心,从而进一步降低了启动时间。
网络实现
和标准的docker网络实现有些不同,我们知道一个Cube的 pod相当于一个虚拟机,因此Cube的pod可以直接利用原先底层SDN网络为虚拟机提供的能力,实现VPC内Cube和VPC内所有资源的二层互通,以及不同VPC内资源的互相隔离。另外从满足用户需求的角度出发,我们也实现了Cube固定内网IP的功能,即在Cube实例更新的过程中,我们可以保持容器pod IP不变。
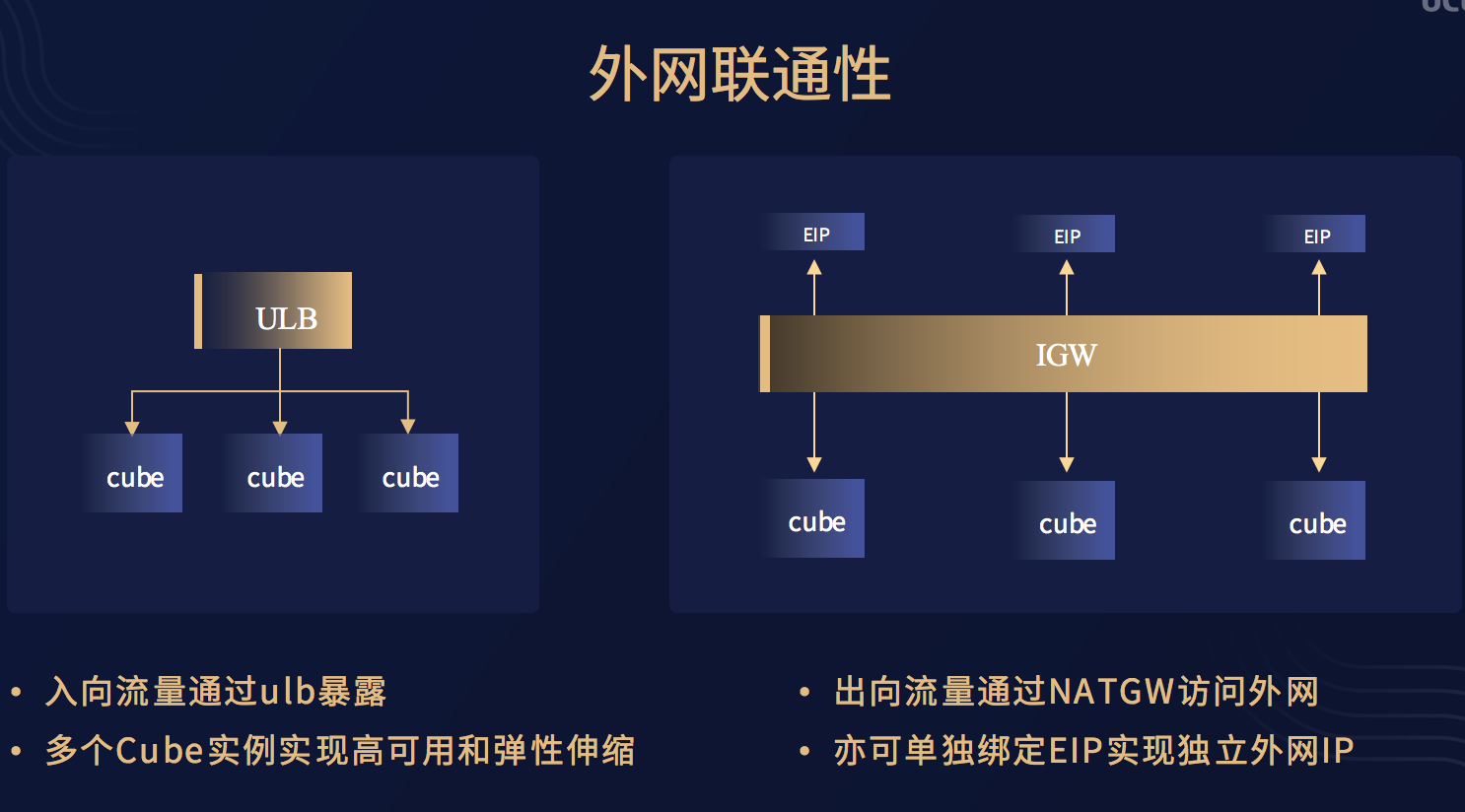
Cube的外网连通性也可以很好利用现有云平台的网络架构,对于入向流量,我们可以将Cube挂在ULB背后,利用多个Cube实例实现高可用和弹性伸缩;对于出向流量,我们也可以通过NETGW来实现Cube对外的访问需求。另外对于需要固定外网IP的情况,我们也可以将单个EIP绑定Cube。
存储实现

Cube的存储也可以很好的对标K8S,主要分为以下几类:一种是K8S内置的Config map Secret和EmptyDir,这些都是作为K8S标准的功能,我们也在Cube实现的CRI中纷纷予以了支持;对于云厂商提供的文件存储、对象存储,我们是通过agent的挂载来实现的,其中文件存储主要是通过agent自动挂载了NFS协议,而对象存储是通过agent挂载了S3fuse的协议;块存储是我们改动比较大的地方,为了提高性能,我们改动了Cube所使用的虚拟机IO路径。通过vhost-user协议,对接到SPDK实现了Cube上高性能RSSD云盘的挂载。
监控和日志的实现
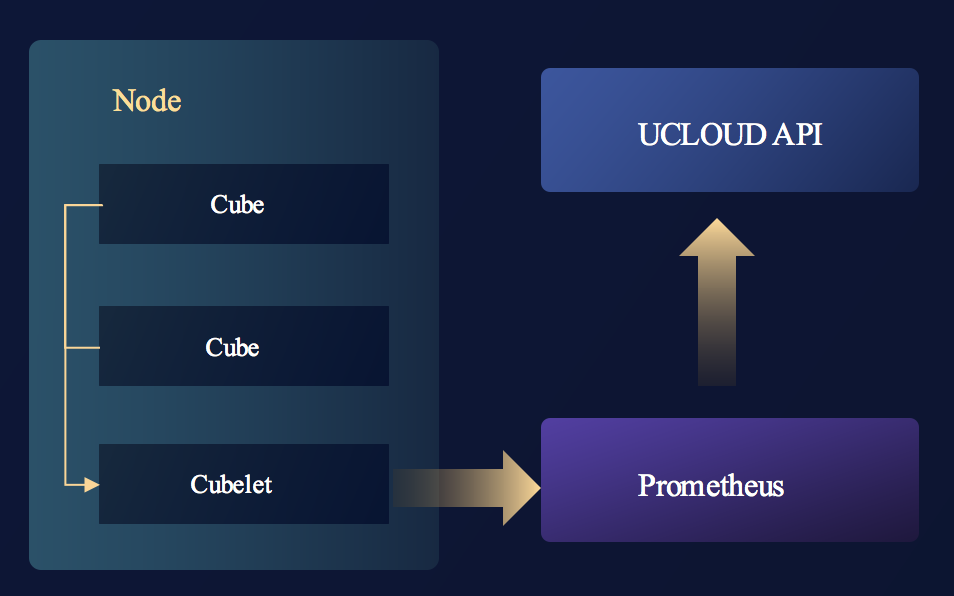
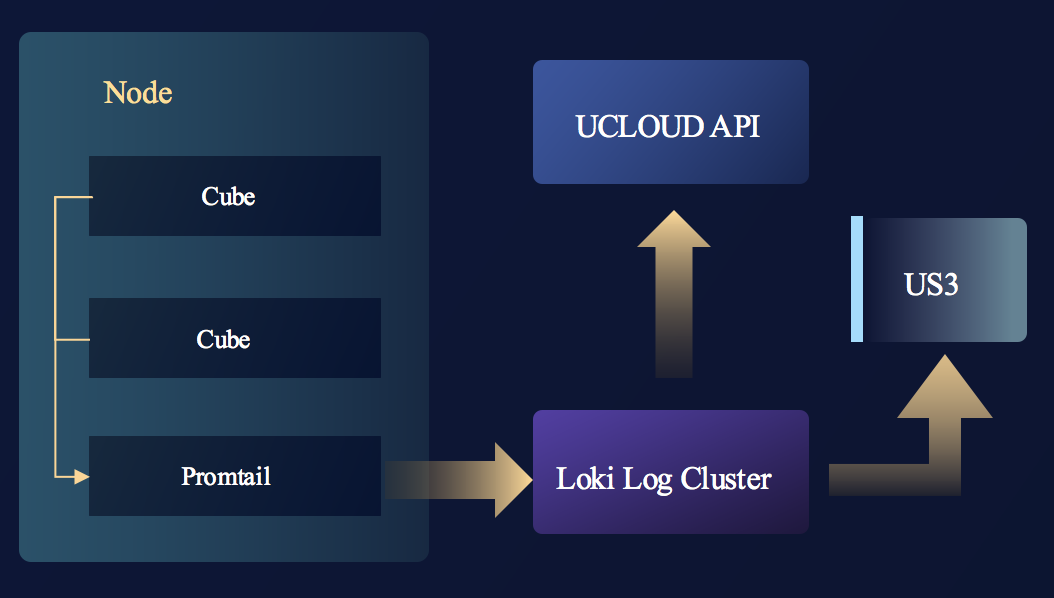
监控和日志这二者的架构比较类似,都是将容器内的信息反馈给用户的一种形式。其中监控信息是通过我们自研的Cubelet组件,将监控信息汇集后上报给prometheus,最终再转发给UCloud API的。而日志信息是通过Promtail采集后转发给Loki Log Cluster集群,再转交给UCloud API,另外对于长期日志,我们还提供了自动转存至对象存储US3的功能。
典型使用场景
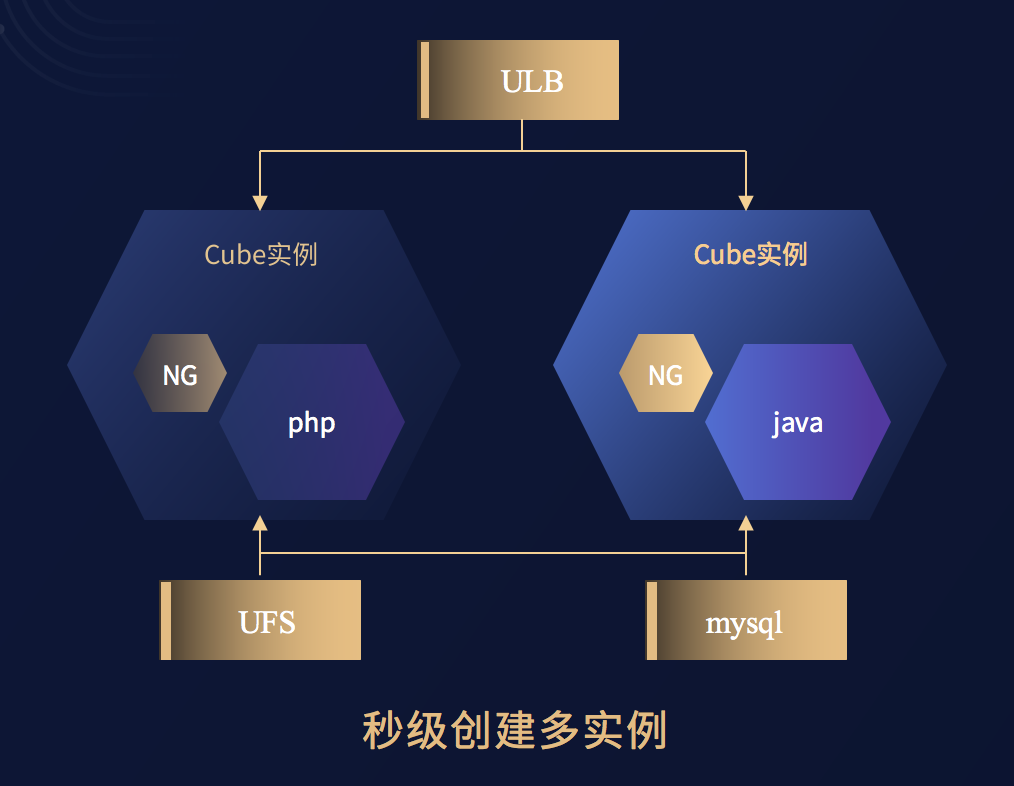
最后,张苗磊分享了一个 Cube比较典型的使用场景,从这个图中我们可以看到所有的计算功能都可以通过Cube容器的实例来提供,而入向流量通过ULB来实现,后接的存储、数据库都可以通过云上原生提供的mysql或者UFS来实现,这样架构可以很好的提供计算、存储分离,并且能够提供快速横向扩展和弹性资源使用的能力。关于这个架构具体的使用情况可以通过B站观看详情。
除此之外,Cube在互联网削峰场景、数据采集、实时音视频转码等场景均可以发挥免服务器运维、秒级启动、自愈性、秒级计费等多重优势,助力企业在容器化应用部署过程中进一步降本增效。








