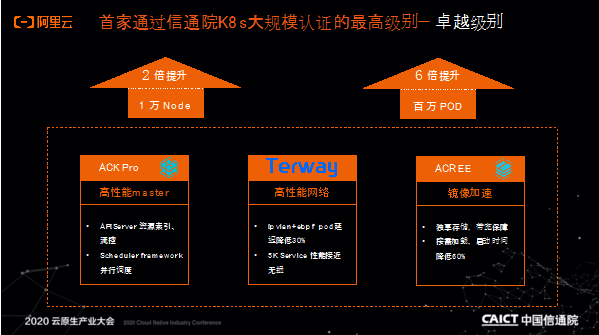
近日,中国信息通信研究院(以下简称“信通院”)在其主办的2020云原生产业大会上,公布了业内首个超大规模容器性能测评结果。阿里云成为率先通过信通院容器规模化性能测试的云服务商,获得最高级别认证—“卓越”级别,并首先成功实现以单集群1万节点1百万 Pod 的规模突破,构建了国内最大规模容器集群,成为引领国内容器落地的技术风向标。

阿里云研究员、阿里云原生技术负责人丁宇
容器规模化落地已成为企业发展“必修课”
疫情加速了企业数字化的发展进程,低延时和高并发的线上场景频繁出现在企业日常经营中,业务创新的需求也在倒逼企业不断运用新兴技术手段。阿里云研究员、阿里云原生技术负责人丁宇表示,“现如今,Kubernetes 逐渐成为云原生时代的基础设施,容器技术被广泛应用于人工智能、大数据、区块链、边缘计算等场景,作为轻量化的计算载体,为更多的场景赋予高度的弹性与敏捷性。”在日常经营和业务创新的双重压力之下,越来越多的企业从小规模试用到全面拥抱容器规模化落地,以保障企业业务能够健康且长远发展。
据信通院《2020年中国云原生用户调查报告》显示,60%以上的用户已在生产环境中应用容器技术,近八成用户的生产需求需要1000及以上的节点规模满足,超过13%的用户容器规模已超过5000节点,9%的用户容器规模大于10000节点。随着云原生技术的进一步普及,越来越多的企业核心业务切换到容器,企业生产环境容器集群规模呈现爆发式增长趋势,容器规模化落地已成为企业发展“必修课”。目前开源版本Kubernetes最多可以支撑5千节点及15万 Pod,已经无法满足日益增长的业务需求。
容器规模化落地企业要过哪些难关
大规模容器集群可以提供更大的业务负载能力,更高的流量突发能力,更加高效的集群管理方式。作为云原生领域的实践者和引领者,阿里云率先实现了单集群 1 万节点1百万 Pod 的规模突破,相比于社区版 Kubernetes,单集群节点数在社区基础上提高了 2 倍,Pod 数提升了 6.7 倍。基于服务百万客户的经验,阿里云沉淀了“容器规模化落地四步走”的路径方法,可帮助企业克服容器规模化落地过程中的难关,轻松应对不断增加的规模化需求。
第一步:如何判断自身是否需要容器集群规模化?
当企业面临流量突发型业务、复杂计算型业务、需进一步提高运维效率等业务或 IT 诉求,单集群的容量成为当前掣肘发展的瓶颈。例如基因计算、在线秒杀等业务,会在短时间会产生大量的负载,对单集群能容纳的计算资源提出了严峻的挑战,亟需单个集群能够支持大规模的节点来批量运行 Pod。基于此,企业就要开始考虑集群扩容了,不过追求集群规模大,并不是一针见效的万能“银弹”, 企业需要根据自身业务发展特性,优化集群能力实现业务价值,盲目追求集群规模化将扩大整个故障域的风险。
第二步:容器规模化不是简单扩大规模的大小,如何自下而上实现一整套体系优化,打通任督二脉?
Kubernetes作为云原生时代的操作系统,其自身及其部署的云环境是非常复杂庞大的,因此容器规模化是从底层云资源到上层应用的一整套优化体系。企业用户需要重点解决三个层面的优化,1、在云产品层面打破对云资源配额的限制;2、在集群组件层面提升资源规模化的天花板;3、在Kubernetes资源层面优化集群配置策略来保证资源规模化能力。
第三步:容器规模化后难以保障原有性能不受损,如何实现性能进一步提升,做个“灵活的巨人”?
容器集群规模被放大N倍之后,对存储、集群网络、应用分发等性能都提出了巨大挑战,例如大规模集群数据中心内网络流量通常较大,网络延迟与抖动的问题也会随之被放大,影响集群网络传输效率和集群稳定。还有大规模集群下批量发布更新应用的常规场景,1w个节点瞬时的镜像拉取会产生巨大的网络冲击,给镜像服务和网络带宽带来了巨大的压力。容器规模化的初衷是提供更强大的技术支撑力,不仅要保障原有性能,还需要进一步提升整体性能。企业用户可重点从四个方面入手优化:Node&Pod规模化效率、网络效率(吞吐与延迟)、DNS解析效率、镜像加速。
第四步:容器规模化后最惊心动魄的难关是“稳定”
如果说集群规模化是第一步,那么稳定的运行上万节点的集群才是更加惊心动魄的,庞大的系统最重要的就是控制故障域,防止雪崩。相对于规模而言,容器规模化后的稳定性更加重要,因为大规模集群的恢复不是简单的重启就能够解决的,一旦雪崩开始,整体崩溃不可避免,严重影响业务接续性。对于企业而言,大规模集群的稳定性就是业务在线的安全性。企业用户重点需要考虑事前止血预案、资源索引和系统组件优化、以及监控所有节点随时启动自愈流程。
阿里云帮助企业一站式实现容器规模化落地
针对大规模集群在企业落地的种种难关,阿里云基于ACK Pro提供了企业级的容器集群管理能力,在APIServer和调度器上提供了大量性能优化,打破资源规模限制、提升性能天花板、保证集群稳定性。通过自研高性能容器网络Terway,优化Pod延迟30%,降低大规模Service的性能开销,不仅可解决大规模集群的网络瓶颈问题,而且提供几乎云上原生的网络性能,使得集群响应更迅速。企业级镜像仓库ACR EE支持独享存储,提供按需加载镜像的能力,降低启动时间60%,可解决大规模节点拉取镜像慢的问题。
整合阿里云存储、网络和安全能力,阿里云一站式为企业提供容器规模化运行的最佳性能:更加高效的网络转发、更强扩展能力的存储、更高效的应用与镜像分发、更稳定的大规模集群管理。
值得一提的是,在信通院的容器规模化测评中,阿里云容器服务的满负载压力测试、网络延时、网络性能损耗等多项测评结果,在参与测评的厂商中遥遥领先。
基于此,阿里云拥有足够弹性的“服务能力空间”,可根据企业业务量身定制满足当前所需的容器集群服务,除了支撑阿里集团内部核心系统容器化上云和阿里云的云产品本身,也将多年的大规模容器技术以产品化的能力输出给众多围绕双十一的生态公司和ISV公司。通过支撑来自全球各行各业的容器云,阿里云容器服务已经沉淀了支持单元化架构、全球化架构、柔性架构的云原生应用托管中台能力,管理了超过1万个以上的容器集群,提供企业级可靠服务。
阿里云拥有国内规模最大的容器集群、最丰富的云原生产品家族和最全面的开源贡献,提供云原生裸金属服务器、云原生数据库、数据仓库、数据湖、容器、微服务、DevOps、Serverless等超过100款创新产品,覆盖新零售、政务、医疗、交通、教育等各个领域。阿里云容器服务是国内唯一连续两次入选Gartner 2019年和2020年《竞争格局:公共云容器服务》报告的厂商,阿里云覆盖Serverless Kubernetes、服务网格、容器镜像等九项产品能力,与 AWS 平齐,产品丰富度领先 Google、微软、IBM 和 Oracle 四家厂商。
随着容器技术的逐渐普及,如何评价容器性能高低成为业内普遍关注的议题。针对行业痛点,中国信息通信研究院发布的业内首个超大规模容器性能测评结果,客观真实反映了容器集群组件级的性能表现。在2020云原生产业大会上,阿里云研究员、阿里云原生技术负责人丁宇表示,“阿里云一直致力于推动云原生在国内的普及,将与信通院一起促进中国容器市场的规范化、标准化发展。”








