1.概述

什么是 KubeSphere Console?
KubeSphere Console 是 KubeSphere 集群的 Web UI 管理平台,提供可视化的方式管理 K8s 集群资源。
KubeSphere Console 对于用户意味着什么?
它可以帮助用户快速浏览集群当前运营状态,比如 CPU 消耗、内存消耗以及各个节点的健康状态。提供了可视化的方式,帮助用户快速创建 K8s 的资源。实时状态更新及详细的数据展示可以让平台资源对用户更透明。内置应用商店,帮助开发者在开发过程中快速部署一些常用的 App。
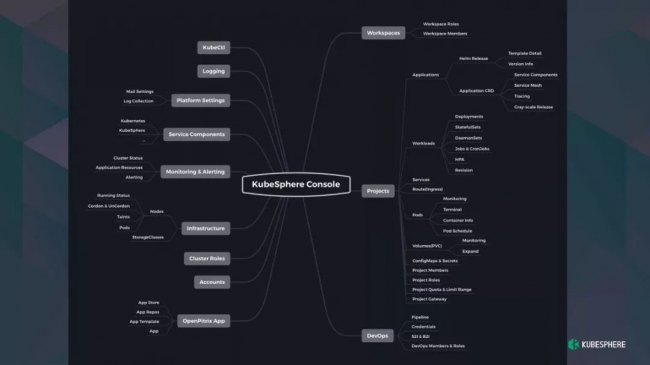
KubeSphere 提供的远不止这些。这是 KubeSphere 目前前端的功能图,除了 K8s 基本的资源管理功能外,还有 DevOps、日志、监控、微服务、灰度发布等功能。

在项目开发上,截至 2.1.0,KubeSphere Console 总共经历了 6 大版本,12 个主要功能点,3365 个 Git Commits,总共 11 个代码贡献者。目前 KubeSphere Console 已经在 GitHub 上开源了。
为什么要做开源这件事?一是响应社区的号召,二是开发者参与到 KubeSphere 里,我们鼓励和欢迎这样的事情。希望能够和社区一起把 KubeSphere 建立得更加强大。
2.前端架构
接下来跟大家介绍 KubeSphere Console 的前端架构。可以从两部分来说,我们主要采用前端 Server 和 Web UI 的架构。前端 Server 是基于 Node.js 和 Koa.js 开发,主要负责 API 转发、登录逻辑控制、配置文件写入等。Web 端是一个标准的 SPA 应用。
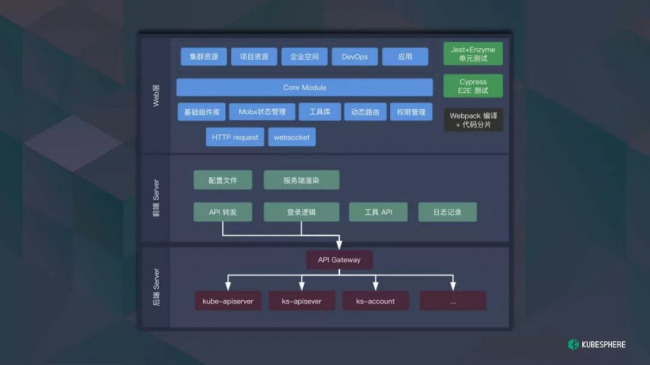
为什么选择前端 Server,而不是像大部分的 Web 用 Nginx 托管?

前端 Server 在完成静态页面托管、API 转发的功能及前提之下,还可以完成其他的功能。使用前端 Server,页面从前端 Server 输出,可以动态注入信息,比如配置文件、运行时、配置编码,还有用户的登录信息,不用你们在页面里,它可以提前写好,UI 加载过程更加流畅。
还有一些登录,像验证码、登录错误提示,比如验证码,如果前端来做会更好,放在后端的话很难找到合适的地方。像前端页面提供 API,比如有一些比较复杂的应用需要一些数据,这些数据在 Server 里,不只是单纯写在 js 里,而是采用 API 的形式,采用 API 形式的话可以让我们拥有更好的定制能力,在不同的环境下是不一样的。

接下来我来说 Web 层的技术,分为以下四部分:技术栈、组件化 UI、状态管理和测试。

技术栈是常用的 React+Mobx.js。组件化 UI 是数据驱动。为什么选择这样的技术栈?人生苦短,当然选择最简单来做就完事了。React+Mobx.js 在我们项目中的特点是具有轻量,比较容易学习,可以让我们更加专注业务开发。
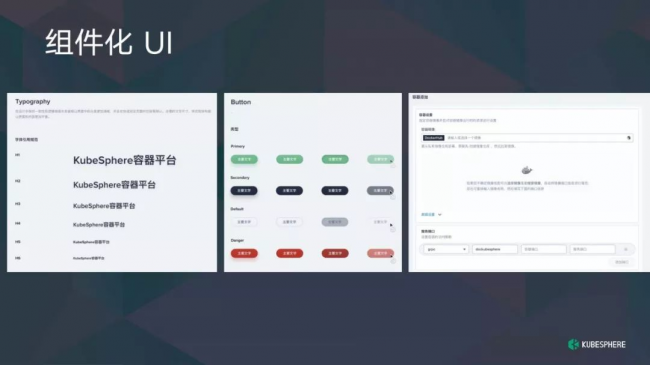
在 Web UI,我们采用组件化方式进行构建,遵循原则和设计方法。什么是原则设计方法呢?很多人了解过,在此跟大家简单介绍。比如基本的标签是 UI 的原子,把这些标签整合起来形成一个简单的组件,比如按钮等这些是分子,我们在分子的基础上增加业务逻辑,把这些东西再组合形成模板,添加数据形成页面。

KubeSphere Console 在里面实现了一套技术组件和一些比较复杂的业务组件。比如我们的样式、按钮和容器表单,这些是在 KubeSphere 里进行组件化的实践。这是组的功能,加大我们开发周期。
这是容器组业务组件,它具有高内聚低耦合的特征。它输入的话只需要 labelSelector 进行筛选。筛选完之后可以输出关联、数据以及 Porter 里的容器信息,以及相关的监控数据,监听 websocket,实时刷新列表。这样的组件可以在很多地方部署副本集,很轻松、很容易的复用。
什么是状态管理?
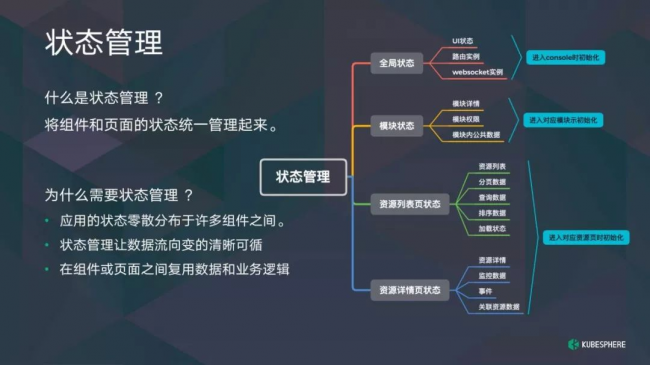
将组件和页面之间的状态统一管理起来,为什么要这样的状态管理?应用的状态影响着分布与许多组件之间,在大型应用里,这样的影响分布会让你的业务逻辑显得很混乱的状态。专门管理可以让数据流向变得清晰可循,可以让数据业务逻辑更容易进行复用。在 KubeSphere Console 里大概分为四层状态管理,在全局 Store 里进行全局 UI 管理,websocket 实例,路由实例等。
模块管理,它是在某一个模块进入时初始化,退出的时候进行销毁。我们在 KubeSphere Console 前面将业务划分为 DevOps、项目、企业空间等,每个模块进入时,状态管理是独自加载的。分层设计的话可以让页面数据流量显得更清晰,设计周期更加简单。
接下来介绍 KubeSphere Console 测试化。

为什么要有测试?测试是功能交互技术的保障。在单元测试方面,我们采用 Jest+Enzyme 的框架保证技术组件和业务组件的功能正常。我们着重于边界情况的测试,以及针对相关的 Bug Reports 进行覆盖。然后是端到端测试,主要目的是为了保证 UI 功能交互和展示效果上的运行。我们在端到端的测试里,与真实客户端进行交互,在总体上可以保证整个业务板块功能的正常。
3.展望
接下来我们一起探讨 KubeSphere Console 未来的展望。KubeSphere Console 将如何成长?我们考虑到以下三方面:可扩展性、可监测性和业务抽象。
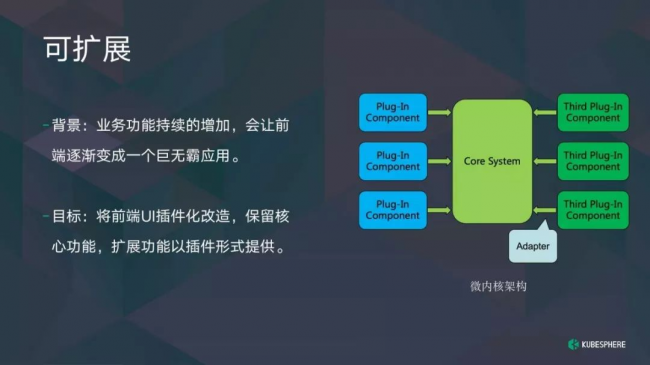
什么是可扩展性?简单的说就是插件化,为什么要做这件事。不管是前端还是后端,只要业务功能持续增加,你的代码容量或者应用会变得庞大无比。进行差异化的改造要让核心模块保留,保留核心业务。其他业务功能以插件的形式加载进来,可以保证主体功能足够轻量。不同用户可以为自己专门的业务场景定制自己的插件。在部署运行时,整个系统看起来没那么多冗余的功能阻碍。

前端页面监测系统,为什么要做这样的功能?因为我们发现很多用户实际前端页面运行场景中经常发生一些错误,我们要帮忙解决时很难复现。监测系统可以帮助记录错误的发生,更容易让我们 Debug。主要包括异常监控、资源请求监控以及页面加载性能的监控,将监控信息、报错信息上传到特定的服务器上,有一个地方专门掌控前端的异常反馈,更容易帮助我们 Debug。

接下来是业务抽象。我们了解到很多用户对 K8s 的基础概念,比如 Pods 或者 workload 控制器,Depolyment,StatfulSet 等,不是很了解,也不知道怎么做选择。我们考虑到这一点,打算在 KubeSphere Console 里针对基础的资源进行一层抽象,让一些用户不用了解底层具体用了什么资源,而是它需要什么样的资源。用户需要某个服务,做出一些配置上的选择,我们来决定底层是什么样的资源实现。这样可以让一些用户更容易使用 KubeSphere。
今年的 Cloud Native + Open Source Virtual Summit China 中国峰会将首次以线上形式召开,KubeSphere 团队为大家准备精彩话题及丰富的周边礼品,扫码直达,千万不要错过哦。









